
Migrate data from InfluxDB Cloud to InfluxDB OSS
To migrate data from InfluxDB Cloud to InfluxDB OSS, query the data from InfluxDB Cloud and write the data to InfluxDB OSS. Because full data migrations will likely exceed your organization’s limits and adjustable quotas, migrate your data in batches.
The following guide provides instructions for setting up an InfluxDB OSS task that queries data from an InfluxDB Cloud bucket in time-based batches and writes each batch to an InfluxDB OSS bucket.
All queries against data in InfluxDB Cloud are subject to your organization’s rate limits and adjustable quotas.
- Set up the migration
- Migration task
- Monitor the migration progress
- Troubleshoot migration task failures
Set up the migration
In InfluxDB Cloud, create an API token with read access to the bucket you want to migrate.
In InfluxDB OSS:
Add your InfluxDB Cloud API token as a secret using the key,
INFLUXDB_CLOUD_TOKEN. See Add secrets for more information.Create a bucket to migrate data to.
Create a bucket to store temporary migration metadata.
Create a new task using the provided migration task. Update the necessary migration configuration options.
(Optional) Set up migration monitoring.
Save the task.
Newly-created tasks are enabled by default, so the data migration begins when you save the task.
After the migration is complete, each subsequent migration task execution will fail with the following error:
error exhausting result iterator: error calling function "die" @41:9-41:86:
Batch range is beyond the migration range. Migration is complete.Migration task
Configure the migration
Specify how often you want the task to run using the
task.everyoption. See Determine your task interval.Define the following properties in the
migrationrecord:migration
- start: Earliest time to include in the migration. See Determine your migration start time.
- stop: Latest time to include in the migration.
- batchInterval: Duration of each time-based batch. See Determine your batch interval.
- batchBucket: InfluxDB OSS bucket to store migration batch metadata in.
- sourceHost: InfluxDB Cloud region URL to migrate data from.
- sourceOrg: InfluxDB Cloud organization to migrate data from.
- sourceToken: InfluxDB Cloud API token. To keep the API token secure, store it as a secret in InfluxDB OSS.
- sourceBucket: InfluxDB Cloud bucket to migrate data from.
- destinationBucket: InfluxDB OSS bucket to migrate data to.
Migration Flux script
import "array"
import "experimental"
import "influxdata/influxdb/secrets"
// Configure the task
option task = {every: 5m, name: "Migrate data from InfluxDB Cloud"}
// Configure the migration
migration = {
start: 2022-01-01T00:00:00Z,
stop: 2022-02-01T00:00:00Z,
batchInterval: 1h,
batchBucket: "migration",
sourceHost: "https://cloud2.influxdata.com",
sourceOrg: "example-cloud-org",
sourceToken: secrets.get(key: "INFLUXDB_CLOUD_TOKEN"),
sourceBucket: "example-cloud-bucket",
destinationBucket: "example-oss-bucket",
}
// batchRange dynamically returns a record with start and stop properties for
// the current batch. It queries migration metadata stored in the
// `migration.batchBucket` to determine the stop time of the previous batch.
// It uses the previous stop time as the new start time for the current batch
// and adds the `migration.batchInterval` to determine the current batch stop time.
batchRange = () => {
_lastBatchStop =
(from(bucket: migration.batchBucket)
|> range(start: migration.start)
|> filter(fn: (r) => r._field == "batch_stop")
|> filter(fn: (r) => r.srcOrg == migration.sourceOrg)
|> filter(fn: (r) => r.srcBucket == migration.sourceBucket)
|> last()
|> findRecord(fn: (key) => true, idx: 0))._value
_batchStart =
if exists _lastBatchStop then
time(v: _lastBatchStop)
else
migration.start
return {start: _batchStart, stop: experimental.addDuration(d: migration.batchInterval, to: _batchStart)}
}
// Define a static record with batch start and stop time properties
batch = {start: batchRange().start, stop: batchRange().stop}
// Check to see if the current batch start time is beyond the migration.stop
// time and exit with an error if it is.
finished =
if batch.start >= migration.stop then
die(msg: "Batch range is beyond the migration range. Migration is complete.")
else
"Migration in progress"
// Query all data from the specified source bucket within the batch-defined time
// range. To limit migrated data by measurement, tag, or field, add a `filter()`
// function after `range()` with the appropriate predicate fn.
data = () =>
from(host: migration.sourceHost, org: migration.sourceOrg, token: migration.sourceToken, bucket: migration.sourceBucket)
|> range(start: batch.start, stop: batch.stop)
// rowCount is a stream of tables that contains the number of rows returned in
// the batch and is used to generate batch metadata.
rowCount =
data()
|> count()
|> group(columns: ["_start", "_stop"])
|> sum()
// emptyRange is a stream of tables that acts as filler data if the batch is
// empty. This is used to generate batch metadata for empty batches and is
// necessary to correctly increment the time range for the next batch.
emptyRange = array.from(rows: [{_start: batch.start, _stop: batch.stop, _value: 0}])
// metadata returns a stream of tables representing batch metadata.
metadata = () => {
_input =
if exists (rowCount |> findRecord(fn: (key) => true, idx: 0))._value then
rowCount
else
emptyRange
return
_input
|> map(
fn: (r) =>
({
_time: now(),
_measurement: "batches",
srcOrg: migration.sourceOrg,
srcBucket: migration.sourceBucket,
dstBucket: migration.destinationBucket,
batch_start: string(v: batch.start),
batch_stop: string(v: batch.stop),
rows: r._value,
percent_complete:
float(v: int(v: r._stop) - int(v: migration.start)) / float(
v: int(v: migration.stop) - int(v: migration.start),
) * 100.0,
}),
)
|> group(columns: ["_measurement", "srcOrg", "srcBucket", "dstBucket"])
}
// Write the queried data to the specified InfluxDB OSS bucket.
data()
|> to(bucket: migration.destinationBucket)
// Generate and store batch metadata in the migration.batchBucket.
metadata()
|> experimental.to(bucket: migration.batchBucket)Configuration help
Monitor the migration progress
The InfluxDB Cloud Migration Community template installs the migration task outlined in this guide as well as a dashboard for monitoring running data migrations.
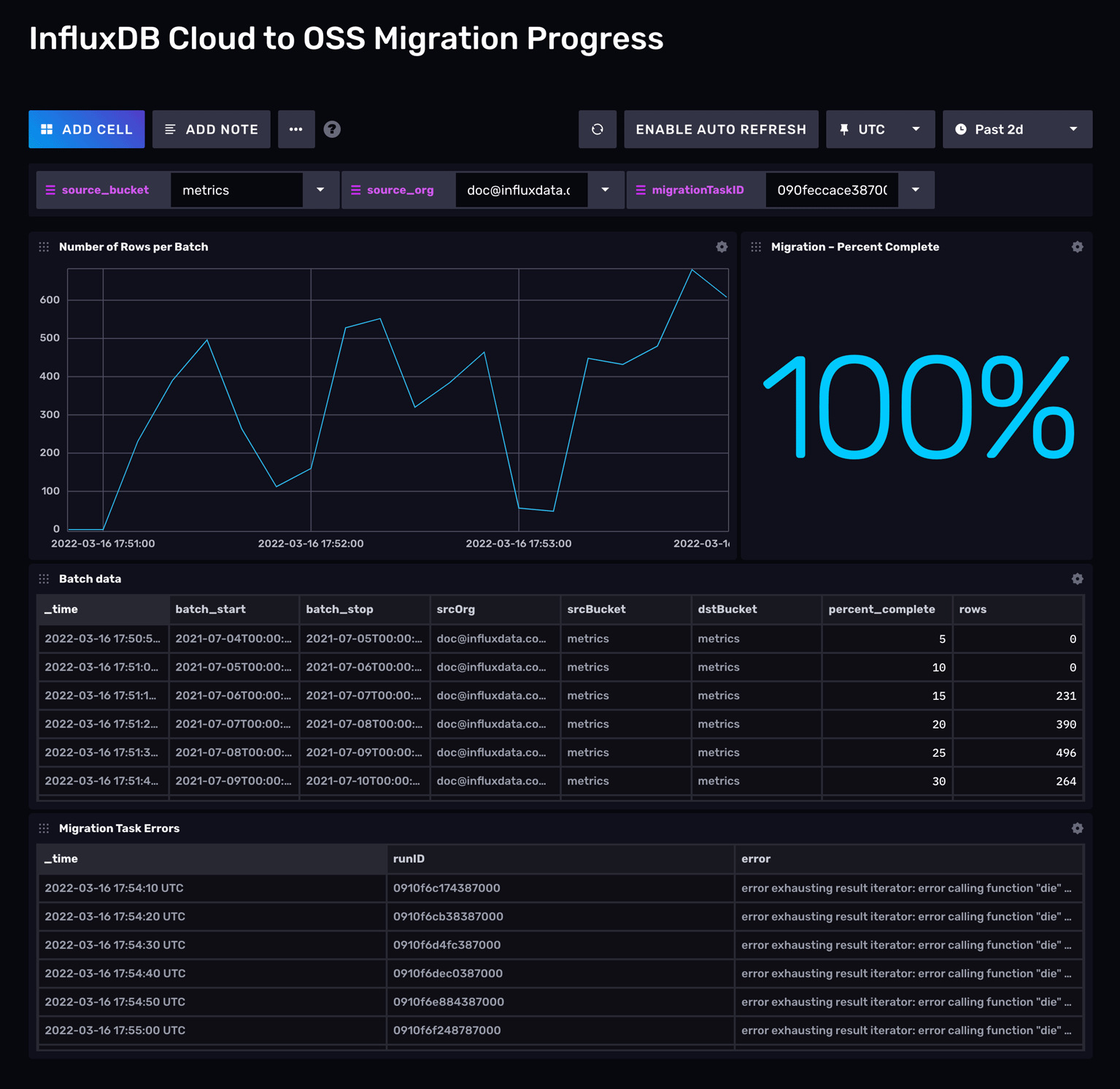
Install the InfluxDB Cloud Migration template
Troubleshoot migration task failures
If the migration task fails, view your task logs to identify the specific error. Below are common causes of migration task failures.
Exceeded rate limits
If your data migration causes you to exceed your InfluxDB Cloud organization’s limits and quotas, the task will return an error similar to:
too many requestsPossible solutions:
- Update the
migration.batchIntervalsetting in your migration task to use a smaller interval. Each batch will then query less data.
Invalid API token
If the API token you add as the INFLUXDB_CLOUD_SECRET doesn’t have read access to
your InfluxDB Cloud bucket, the task will return an error similar to:
unauthorized accessPossible solutions:
- Ensure the API token has read access to your InfluxDB Cloud bucket.
- Generate a new InfluxDB Cloud API token with read access to the bucket you
want to migrate. Then, update the
INFLUXDB_CLOUD_TOKENsecret in your InfluxDB OSS instance with the new token.
Query timeout
The InfluxDB Cloud query timeout is 90 seconds. If it takes longer than this to return the data from the batch interval, the query will time out and the task will fail.
Possible solutions:
- Update the
migration.batchIntervalsetting in your migration task to use a smaller interval. Each batch will then query less data and take less time to return results.
Batch size is too large
If your batch size is too large, the task returns an error similar to the following:
internal error: error calling function "metadata" @97:1-97:11: error calling function "findRecord" @67:32-67:69: wrong number of fieldsPossible solutions:
- Update the
migration.batchIntervalsetting in your migration task to use a smaller interval and retrieve less data per batch.
Was this page helpful?
Thank you for your feedback!
Support and feedback
Thank you for being part of our community! We welcome and encourage your feedback and bug reports for InfluxDB and this documentation. To find support, use the following resources:
Customers with an annual or support contract can contact InfluxData Support.