
Define custom partitions
Use the Admin UI, the influxctl CLI, or the Management HTTP API
to define custom partition strategies when creating a database or table.
By default, InfluxDB Cloud Dedicated partitions data by day.
The partitioning strategy of a database or table is determined by a partition template which defines the naming pattern for partition keys. Partition keys uniquely identify each partition. When a partition template is applied to a database, it becomes the default template for all tables in that database, but can be overridden when creating a table.
- Create a database with a custom partition template
- Create a table with a custom partition template
- Partition template requirements and guidelines
- Example partition templates
Create a database with a custom partition template
The following examples show how to create a new example-db database and apply a partition
template that partitions by distinct values of two tags (room and sensor-type),
bucketed values of the customerID tag, and by day using the time format %Y-%m-%d:
influxctl database create \
--template-tag room \
--template-tag sensor-type \
--template-tag-bucket customerID,500 \
--template-timeformat '%Y-%m-%d' \
example-dbThe following command flags identify partition template parts:
--template-timeformat: A Rust strftime date and time string that specifies the time part in the partition template and determines the time interval to partition by. Use one of the following:%Y-%m-%d(daily)%Y-%m(monthly)%Y(annually)
--template-tag: An InfluxDB tag to use in the partition template.--template-tag-bucket: An InfluxDB tag and number of “buckets” to group tag values into. Provide the tag key and the number of buckets to bucket tag values into separated by a comma:tagKey,N.
curl \
--location "https://console.influxdata.com/api/v0/accounts/ACCOUNT_ID/clusters/CLUSTER_ID/databases" \
--header "Authorization: Bearer MANAGEMENT_TOKEN" \
--json '{
"name": "example-db",
"maxTables": 500,
"maxColumnsPerTable": 250,
"retentionPeriod": 2592000000000,
"partitionTemplate": [
{ "type": "tag", "value": "room" },
{ "type": "tag", "value": "sensor-type" },
{ "type": "bucket", "value": { "tagName": "customerID", "numberOfBuckets": 500 } },
{ "type": "time", "value": "%Y-%m-%d" }
]
}'Replace the following in your request:
ACCOUNT_ID: the account ID for the cluster (list details via the Admin UI or CLI)CLUSTER_ID: the cluster ID (list details via the Admin UI or CLI).MANAGEMENT TOKEN: a valid management token for your InfluxDB Cloud Dedicated cluster
The partitionTemplate property in the request body
is an array of JSON objects that identify the partition template parts.
Create a table with a custom partition template
The following example creates a new example-table table in the example-db database and applies a partition template that partitions by distinct values of
two tags (room and sensor-type), bucketed values of the customerID tag,
and by month using the time format %Y-%m:
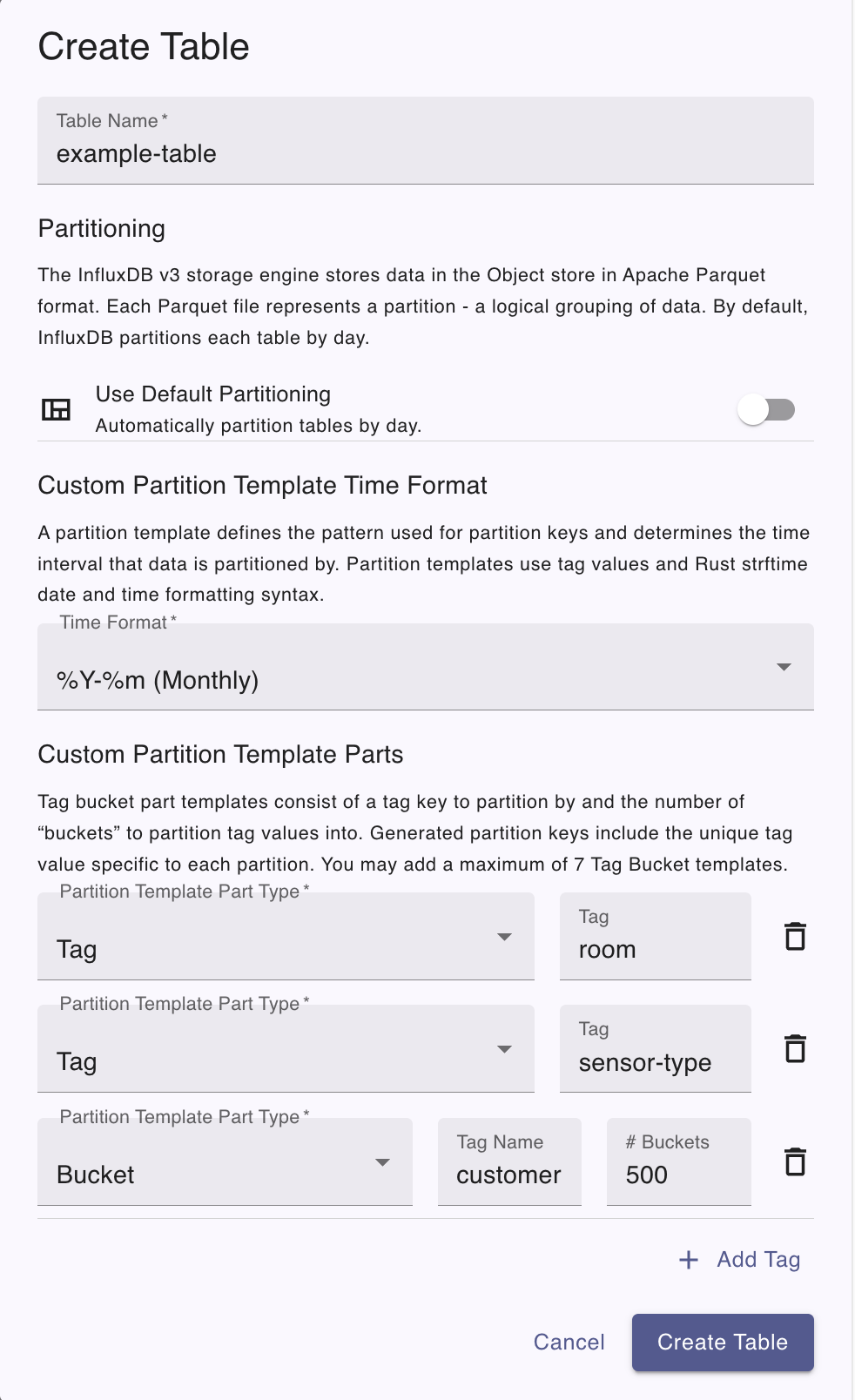
The InfluxDB Cloud Dedicated Admin UI lets you apply a custom partition template when creating a table.
To access the InfluxDB Cloud Dedicated Admin UI, visit the following URL in your browser:
https://console.influxdata.com
In the cluster list, click the cluster you want to manage.
Create the
example-dbdatabase or click the row of an existing database.Click the New Table button above the table list.
In the Create Table dialog:
- Set Table name to
example-table. - If the Use default partitioning toggle is on, turn it off to enable custom partitioning.
- Under Custom partition template time format, set the time format to
%Y-%m. - Under Custom partition template parts:
- In the Partition template part type dropdown, click Tag, set Tag name to
room. - Click Add Tag.
- In the Partition template part type dropdown, click Tag, set Tag name to
sensor-type. - Click Add Tag.
- In the Partition template part type dropdown, click Bucket, set Tag name to
customerIDand Buckets to500. - Click Create Table to apply the template.
influxctl table create \
--template-tag room \
--template-tag sensor-type \
--template-tag-bucket customerID,500 \
--template-timeformat '%Y-%m' \
example-db \
example-tablecurl \
--location "https://console.influxdata.com/api/v0/accounts/ACCOUNT_ID/clusters/CLUSTER_ID/databases/example-db/tables" \
--request POST \
--header "Authorization: Bearer MANAGEMENT_TOKEN" \
--json '{
"name": "example-table",
"partitionTemplate": [
{ "type": "tag", "value": "room" },
{ "type": "tag", "value": "sensor-type" },
{ "type": "bucket", "value": { "tagName": "customerID", "numberOfBuckets": 500 } },
{ "type": "time", "value": "%Y-%m" }
]
}'Replace the following in your request:
Partition template requirements and guidelines
Always specify 1 time part in your template. A template has a maximum of 8 parts: 1 time part and up to 7 total tag and tag bucket parts.
For more information about partition template requirements and restrictions, see Partition templates.
Partition templates can only be applied on create
You can only apply a partition template when creating a database. You can’t update a partition template on an existing database.
Example partition templates
Given the following line protocol
with a 2024-01-01T00:00:00Z timestamp:
prod,line=A,station=weld1 temp=81.9,qty=36i 1704067200000000000The following tables show how the partition key is generated based on the partition template parts you provide.
Partitioning by distinct tag values
| Description | Tag parts | Time part | Resulting partition key |
|---|---|---|---|
| By day (default) | %Y-%m-%d | 2024-01-01 | |
| By month | %Y-%m | 2024-01 | |
| By year | %Y | 2024 | |
| Single tag, by day | line | %Y-%m-%d | A | 2024-01-01 |
| Single tag, by month | line | %Y-%m | A | 2024-01 |
| Single tag, by year | line | %Y | A | 2024 |
| Multiple tags, by day | line, station | %Y-%m-%d | A | weld1 | 2024-01-01 |
| Multiple tags, by month | line, station | %Y-%m | A | weld1 | 2024-01 |
| Multiple tags, by year | line, station | %Y | A | weld1 | 2024 |
Partition by tag buckets
| Description | Tag part | Tag bucket part | Time part | Resulting partition key |
|---|---|---|---|---|
| Distinct tag, tag buckets, by day | line | station,100 | %Y-%m-%d | A | 3 | 2024-01-01 |
| Distinct tag, tag buckets, by month | line | station,500 | %Y-%m | A | 303 | 2024-01 |
Was this page helpful?
Thank you for your feedback!
Support and feedback
Thank you for being part of our community! We welcome and encourage your feedback and bug reports for InfluxDB Cloud Dedicated and this documentation. To find support, use the following resources:
Customers with an annual or support contract can contact InfluxData Support.