
Create a database
Use the Admin UI, the influxctl CLI,
or the Management HTTP API to create a database in your InfluxDB Cloud Dedicated cluster.
You can create a database with an optional retention period and custom partitioning.
- Create a database
- Create a database with custom partitioning
- Partition template requirements and guidelines
- Database attributes
Create a database
Open the InfluxDB Cloud Dedicated Admin UI at
https://console.influxdata.com
Use the credentials provided by InfluxData to log into the Admin UI. If you don’t have login credentials, contact InfluxData support.
In the cluster list, find and click the cluster you want to create a database in. You can sort on column headers or use the Search field to find a specific cluster.
Click the New Database button above the database list. The Create Database dialog displays.
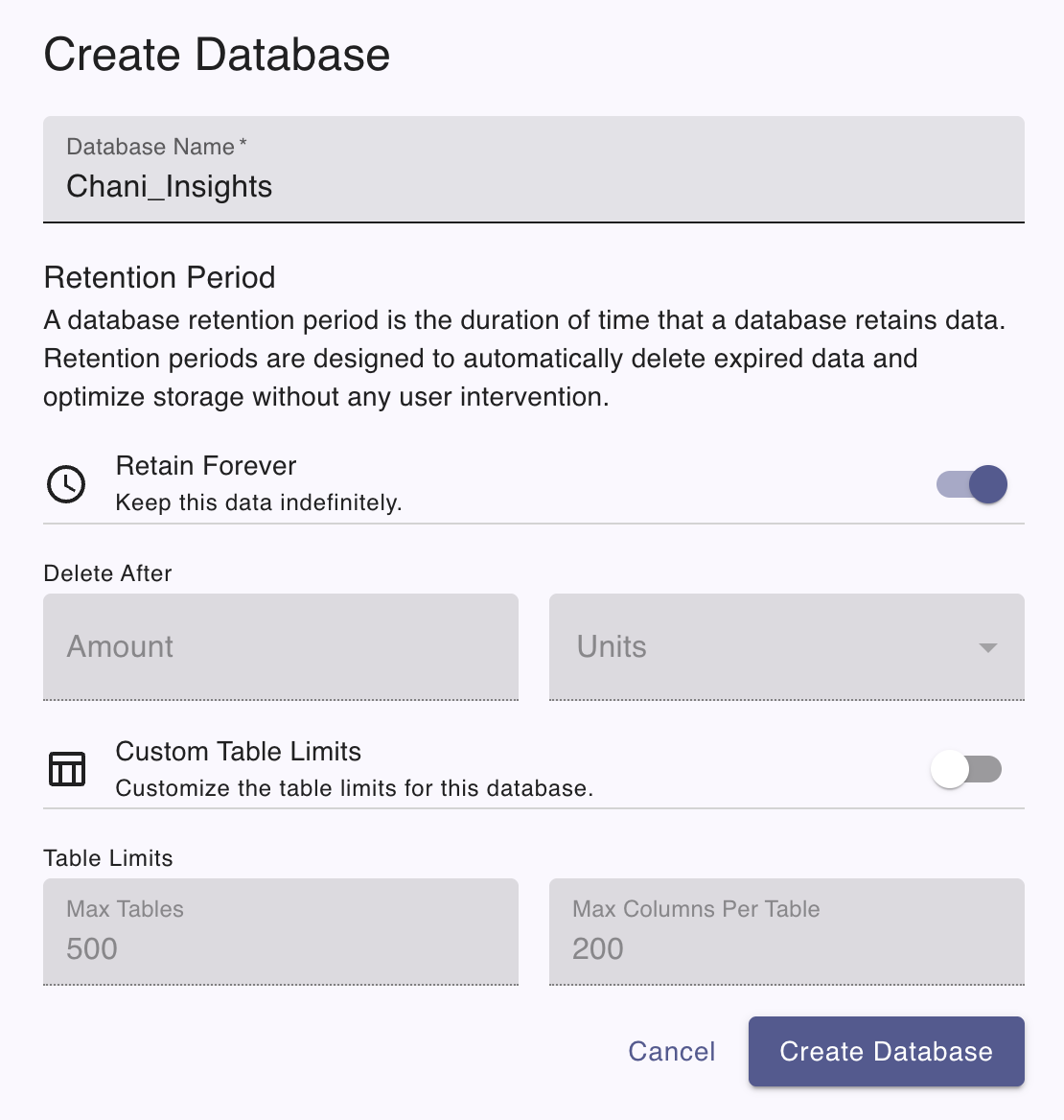
In the Create Database dialog, provide the following information:
- Database name: The name of the database to create. See Database naming restrictions.
- Retention period: The retention period for the database. See Retention period syntax.
- Max tables: The maximum number of tables (measurements) allowed in the database. Default is 500.
- Max columns per table: The maximum number of columns allowed in each table (measurement). Default is 250.
Click the Create Database button to create the database. The new database displays in the list of databases for the cluster.
If you haven’t already, download and install the
influxctlCLI, and then configure aninfluxctlconnection profile for your cluster.Run the
influxctl database createcommand:
influxctl database create \
--retention-period 30d \
DATABASE_NAMEReplace DATABASE_NAME with your desired database name.
This example uses cURL to send a Management HTTP API request, but you can use any HTTP client.
- If you haven’t already, follow the instructions to install cURL for your system.
- In your terminal, use cURL to send a request to the following InfluxDB Cloud Dedicated endpoint:
POST https://console.influxdata.com/api/v0/accounts/ACCOUNT_ID/clusters/CLUSTER_ID/databases
curl \
--location "https://console.influxdata.com/api/v0/accounts/ACCOUNT_ID/clusters/CLUSTER_ID/databases" \
--header "Authorization: Bearer MANAGEMENT_TOKEN" \
--json '{
"name": "DATABASE_NAME"
}'Replace the following:
Partitioning defaults to %Y-%m-%d (daily).
Create a database with custom partitioning
InfluxDB Cloud Dedicated lets you define a custom partitioning strategy for each database and table. A partition is a logical grouping of data stored in Apache Parquet By default, data is partitioned by day, but, depending on your schema and workload, customizing the partitioning strategy can improve query performance.
To use custom partitioning, you define a partition template. If a table doesn’t have a custom partition template, it inherits the database’s template.
If you haven’t already, download and install the
influxctlCLI.Use the following
influxctl database createcommand flags to specify the partition template parts:--template-timeformat: A Rust strftime date and time string that specifies the time part in the partition template and determines the time interval to partition by. Use one of the following:%Y-%m-%d(daily)%Y-%m(monthly)%Y(annually)
--template-tag: An [InfluxDB tag] to use in the partition template.--template-tag-bucket: An InfluxDB tag and number of “buckets” to group tag values into. Provide the tag key and the number of buckets to bucket tag values into separated by a comma:tagKey,N.
influxctl database create \
--retention-period 30d \
--template-tag TAG_KEY_1 \
--template-tag TAG_KEY_2 \
--template-tag-bucket TAG_KEY_3,100 \
--template-tag-bucket TAG_KEY_4,300 \
--template-timeformat '%Y-%m-%d' \
DATABASE_NAMEReplace the following:
DATABASE_NAME: the name of the database to createTAG_KEY_1,TAG_KEY_2: tag keys to partition byTAG_KEY_3,TAG_KEY_4: tag keys for bucketed partitioning100,300: number of buckets to group tag values into’%Y-%m-%d’: Rust strftime date and time string that specifies the time part in the partition template
This example uses cURL to send a Management HTTP API request, but you can use any HTTP client.
- If you haven’t already, follow the instructions to install cURL for your system.
- In your terminal, use cURL to send a request to the following InfluxDB Cloud Dedicated endpoint:
POST https://console.influxdata.com/api/v0/accounts/ACCOUNT_ID/clusters/CLUSTER_ID/databases
In the request body, include the partitionTemplate property and specify the partition template parts as an array of objects–for example:
curl \
--location "https://console.influxdata.com/api/v0/accounts/ACCOUNT_ID/clusters/CLUSTER_ID/databases" \
--header "Authorization: Bearer MANAGEMENT_TOKEN" \
--json '{
"name": "DATABASE_NAME",
"maxTables": 500,
"maxColumnsPerTable": 250,
"retentionPeriod": 2592000000000,
"partitionTemplate": [
{ "type": "tag", "value": "TAG_KEY_1" },
{ "type": "tag", "value": "TAG_KEY_2" },
{ "type": "bucket", "value": { "tagName": "TAG_KEY_3", "numberOfBuckets": 100 } },
{ "type": "bucket", "value": { "tagName": "TAG_KEY_4", "numberOfBuckets": 300 } },
{ "type": "time", "value": "%Y-%m-%d" }
]
}'Replace the following:
ACCOUNT_ID: the account ID for the cluster (list details via the Admin UI or CLI)CLUSTER_ID: the cluster ID (list details via the Admin UI or CLI).MANAGEMENT_TOKEN: a valid management token for your InfluxDB Cloud Dedicated clusterDATABASE_NAME: name for the new databaseTAG_KEY_1,TAG_KEY_2: tag keys to partition byTAG_KEY_3,TAG_KEY_4: tag keys for bucketed partitioning100,300: number of buckets to group tag values into’%Y-%m-%d’: Rust strftime date and time string that specifies the time part in the partition template
Partition template requirements and guidelines
Always specify 1 time part in your template. A template has a maximum of 8 parts: 1 time part and up to 7 total tag and tag bucket parts.
For more information about partition template requirements and restrictions, see Partition templates.
Partition templates can only be applied on create
You can only apply a partition template when creating a database. You can’t update a partition template on an existing database.
Database attributes
Retention period syntax
Specify how long InfluxDB retains data before automatically removing it.
Use the --retention-period flag to define the retention period as a duration.
For example, 30d means 30 days. A zero duration (0d) keeps data indefinitely.
Valid duration units
- m: minute
- h: hour
- d: day
- w: week
- mo: month
- y: year
Example values
0d: infinite/none3d: 3 days6w: 6 weeks1mo: 1 month (30 days)1y: 1 year
Use the retentionPeriod property to specify the retention period as nanoseconds.
For example, 2592000000000 means 30 days. A value of 0 keeps data indefinitely.
Example values
0: infinite/none259200000000000: 3 days2592000000000000: 30 days31536000000000000: 1 standard year (365 days)
Database naming restrictions
Database names must adhere to the following naming restrictions:
- Length: Maximum 64 characters
- Allowed characters: Alphanumeric characters (a-z, A-Z, 0-9), underscore (
_), dash (-), and forward-slash (/) - Prohibited characters: Cannot contain whitespace, punctuation, or other special characters
- Starting character: Should start with a letter or number and should not start with underscore (
_) - Case sensitivity: Database names are case-sensitive
Underscore prefix reserved for system use
Names starting with an underscore (_) may be reserved for InfluxDB system use.
While InfluxDB Cloud Dedicated might not explicitly reject these names, using them risks
conflicts with current or future system features and may result in
unexpected behavior or data loss.
Valid database name examples
mydb
sensor_data
prod-metrics
logs/application
webserver123Invalid database name examples
my database # Contains whitespace
sensor.data # Contains period
app@server # Contains special character
_internal # Starts with underscore (reserved)
very_long_database_name_that_exceeds_sixty_four_character_limit # Too longFor comprehensive information about naming restrictions for all InfluxDB identifiers, see Naming restrictions and conventions.
InfluxQL DBRP naming convention
In InfluxDB 1.x, data is stored in databases and retention policies. In InfluxDB Cloud Dedicated, databases and retention policies have been merged into databases, where databases have a retention period, but retention policies are no longer part of the data model.
Because InfluxQL uses the 1.x data model, a database must be mapped to a v1 database and retention policy (DBRP) to be queryable with InfluxQL.
When naming a database that you want to query with InfluxQL, use the following naming convention to automatically map v1 DBRP combinations to an InfluxDB Cloud Dedicated database:
database_name/retention_policy_nameDatabase naming examples
| v1 Database name | v1 Retention Policy name | New database name |
|---|---|---|
| db | rp | db/rp |
| telegraf | autogen | telegraf/autogen |
| webmetrics | 1w-downsampled | webmetrics/1w-downsampled |
Table and column limits
In InfluxDB Cloud Dedicated, table (measurement) and column limits can be configured using the following options:
| Description | Default | influxctl CLI flag | Management API property |
|---|---|---|---|
| Table limit | 500 | --max-tables | maxTables |
| Column limit | 250 | --max-columns | maxColumnsPerTable |
Table limit
Default maximum number of tables: 500
Each measurement is represented by a table in a database. Your database’s table limit can be raised beyond the default limit of 500. InfluxData has production examples of clusters with 20,000+ active tables across multiple databases.
Excessive table counts can impact performance and stability
High table counts, especially those concurrently receiving writes and queries, can increase catalog overhead which can affect performance and stability. What constitutes “excessive” depends on multiple factors such as query latency requirements, write bandwidth, and cluster capacity to handle rapid backfills. If you’re considering more than doubling the default limit, test your configuration thoroughly.
Increasing your table limit affects your InfluxDB Cloud Dedicated cluster in the following ways:
Column limit
Default maximum number of columns: 250
Time, fields, and tags are each represented by a column in a table. Increasing your column limit affects your InfluxDB Cloud Dedicated cluster in the following ways:
Was this page helpful?
Thank you for your feedback!
Support and feedback
Thank you for being part of our community! We welcome and encourage your feedback and bug reports for InfluxDB Cloud Dedicated and this documentation. To find support, use the following resources:
Customers with an annual or support contract can contact InfluxData Support.