
Use the InfluxDB documentation MCP server
The InfluxDB documentation MCP server lets AI tools and agents search InfluxDB documentation directly from your development environment. Use it to find answers, code examples, and configuration details without leaving your IDE.
Why use the documentation MCP server?
When you connect the documentation MCP server to your AI coding assistant, the assistant can search InfluxDB documentation to answer your questions with accurate, up-to-date information. Instead of switching to a browser or guessing at syntax, you can ask questions in your IDE and get responses grounded in official documentation.
Common use cases:
- Get help writing queries, client library code, or CLI commands
- Look up configuration options and environment variables
- Find code examples for specific tasks
- Troubleshoot errors with documentation-backed answers
Install the documentation MCP server
The documentation MCP server is a hosted service—you don’t need to install or run anything locally. Add the server URL to your AI tool’s MCP configuration.
On first use, you’ll be prompted to sign in with Google. This authentication is used only for rate limiting—no personal data is collected.
MCP server URL:
https://influxdb-docs.mcp.kapa.aiThe server uses SSE (Server-Sent Events) transport. For help adding MCP servers, refer to your tool’s documentation or ask your AI assistant.
Authentication and rate limits
When you connect to the documentation MCP server for the first time, a Google sign-in window opens to complete an OAuth/OpenID Connect login.
The hosted MCP server:
- Requests only the
openidscope from Google - Receives an ID token (JWT) containing a stable, opaque user ID
- Does not request
emailorprofilescopes—your name, email address, and other personal data are not collected
The anonymous Google ID enforces per-user rate limits to prevent abuse:
- 40 requests per user per hour
- 200 requests per user per day
On Google’s consent screen, this appears as “Associate you with your personal info on Google.”
This is Google’s generic wording for the openid scope—it means the app can recognize
that the same Google account is signing in again.
It does not grant access to your email, name, contacts, or other data.
Search documentation with the MCP tool
The documentation MCP server exposes a semantic search tool:
search_influxdb_knowledge_sourcesThis tool lets AI agents perform semantic retrieval over InfluxDB documentation and related knowledge sources.
What the tool does:
- Searches all InfluxDB documentation for a given query
- Returns the most relevant chunks in descending order of relevance
- Each chunk is a self-contained snippet from a single documentation page
Response format:
Each result includes:
source_url: URL of the original documentation pagecontent: The chunk content in Markdown
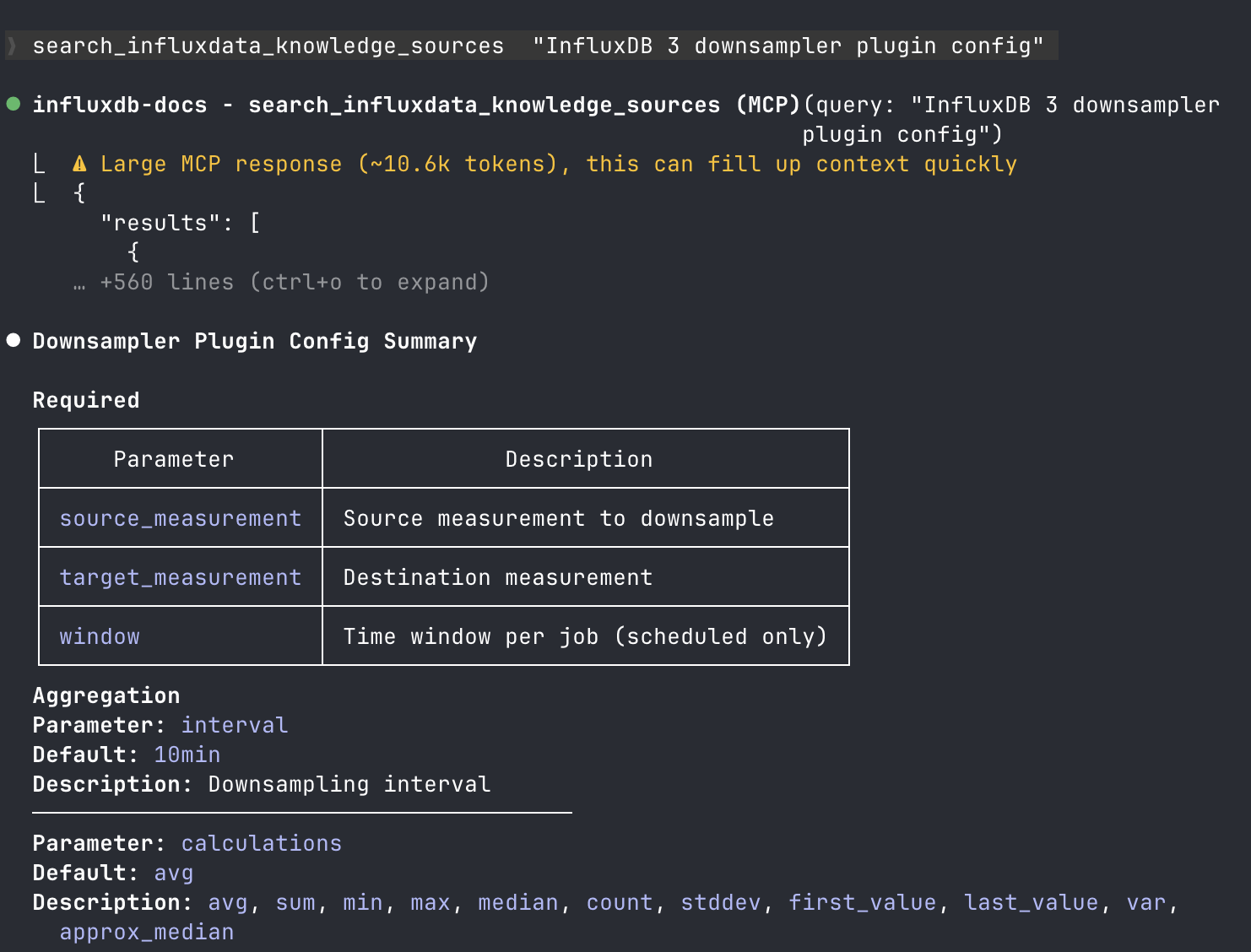
Use the documentation MCP server
After you install the documentation MCP server, your AI assistant can search InfluxDB documentation to help you with tasks. Ask questions naturally—the assistant uses the MCP server to find relevant documentation and provide accurate answers.
Example prompts
“How do I write data to InfluxDB using Python?”
“What’s the syntax for a SQL query with a WHERE clause in InfluxDB?”
“Show me how to configure Telegraf to collect CPU metrics.”
“What environment variables does the InfluxDB CLI use?”
“How do I create a database token with read-only permissions?”
Was this page helpful?
Thank you for your feedback!
Support and feedback
Thank you for being part of our community! We welcome and encourage your feedback and bug reports for InfluxDB and this documentation. To find support, use the following resources:
Customers with an annual or support contract can contact InfluxData Support.