
Use Anti-Entropy service in InfluxDB Enterprise v1
Prior to InfluxDB Enterprise 1.7.2, the Anti-Entropy (AE) service was enabled by default. When shards create digests with lots of time ranges (10s of thousands), some customers have experienced significant performance issues, including CPU usage spikes. If your shards include a small number of time ranges (most have 1 to 10, some have up to several hundreds) and you can benefit from the AE service, enable AE and monitor it closely to see if your performance is adversely impacted.
Introduction
Shard entropy refers to inconsistency among shards in a shard group. This can be due to the “eventually consistent” nature of data stored in InfluxDB Enterprise clusters or due to missing or unreachable shards. The Anti-Entropy (AE) service ensures that each data node has all the shards it owns according to the metastore and that all shards in a shard group are consistent. Missing shards are automatically repaired without operator intervention while out-of-sync shards can be manually queued for repair. This topic covers how the Anti-Entropy service works and some of the basic situations where it takes effect.
Concepts
The Anti-Entropy service is a component of the influxd service available on each of your data nodes. Use this service to ensure that each data node has all of the shards that the metastore says it owns and ensure all shards in a shard group are in sync.
If any shards are missing, the Anti-Entropy service will copy existing shards from other shard owners.
If data inconsistencies are detected among shards in a shard group, invoke the Anti-Entropy service and queue the out-of-sync shards for repair.
In the repair process, the Anti-Entropy service will sync the necessary updates from other shards
within a shard group.
By default, the service performs consistency checks every 5 minutes. This interval can be modified in the anti-entropy.check-interval configuration setting.
The Anti-Entropy service can only address missing or inconsistent shards when there is at least one copy of the shard available. In other words, as long as new and healthy nodes are introduced, a replication factor of 2 can recover from one missing or inconsistent node; a replication factor of 3 can recover from two missing or inconsistent nodes, and so on. A replication factor of 1, which is not recommended, cannot be recovered by the Anti-Entropy service.
Symptoms of entropy
The Anti-Entropy service automatically detects and fixes missing shards, but shard inconsistencies must be manually detected and queued for repair. There are symptoms of entropy that, if seen, would indicate an entropy repair is necessary.
Different results for the same query
When running queries against an InfluxDB Enterprise cluster, each query may be routed to a different data node. If entropy affects data within the queried range, the same query will return different results depending on which node the query runs against.
Query attempt 1
SELECT mean("usage_idle") WHERE time > '2018-06-06T18:00:00Z' AND time < '2018-06-06T18:15:00Z' GROUP BY time(3m) FILL(0)
name: cpu
time mean
---- ----
1528308000000000000 99.11867392974537
1528308180000000000 99.15410822137049
1528308360000000000 99.14927494363032
1528308540000000000 99.1980535465783
1528308720000000000 99.18584290492262Query attempt 2
SELECT mean("usage_idle") WHERE time > '2018-06-06T18:00:00Z' AND time < '2018-06-06T18:15:00Z' GROUP BY time(3m) FILL(0)
name: cpu
time mean
---- ----
1528308000000000000 99.11867392974537
1528308180000000000 0
1528308360000000000 0
1528308540000000000 0
1528308720000000000 99.18584290492262The results indicate that data is missing in the queried time range and entropy is present.
Flapping dashboards
A “flapping” dashboard means data visualizations change when data is refreshed and pulled from a node with entropy (inconsistent data). It is the visual manifestation of getting different results from the same query.
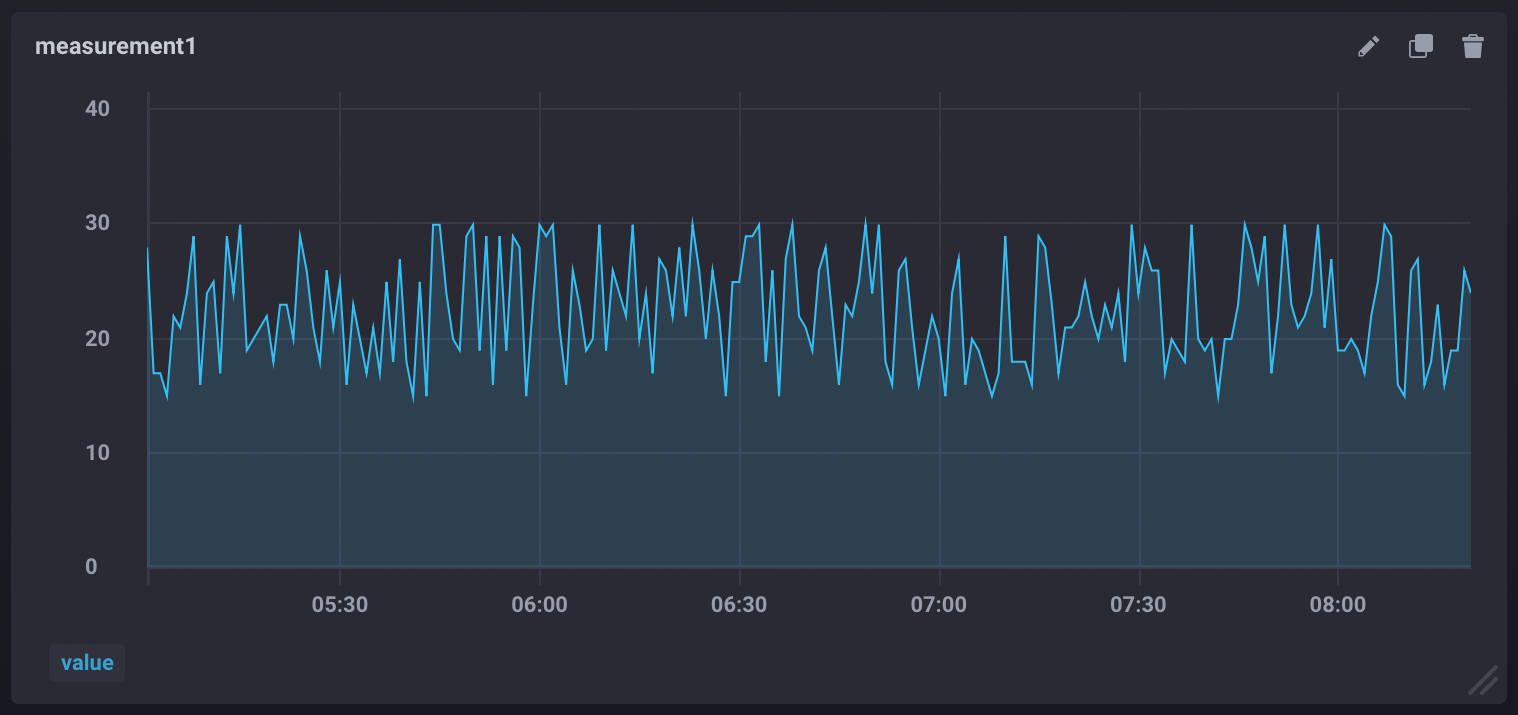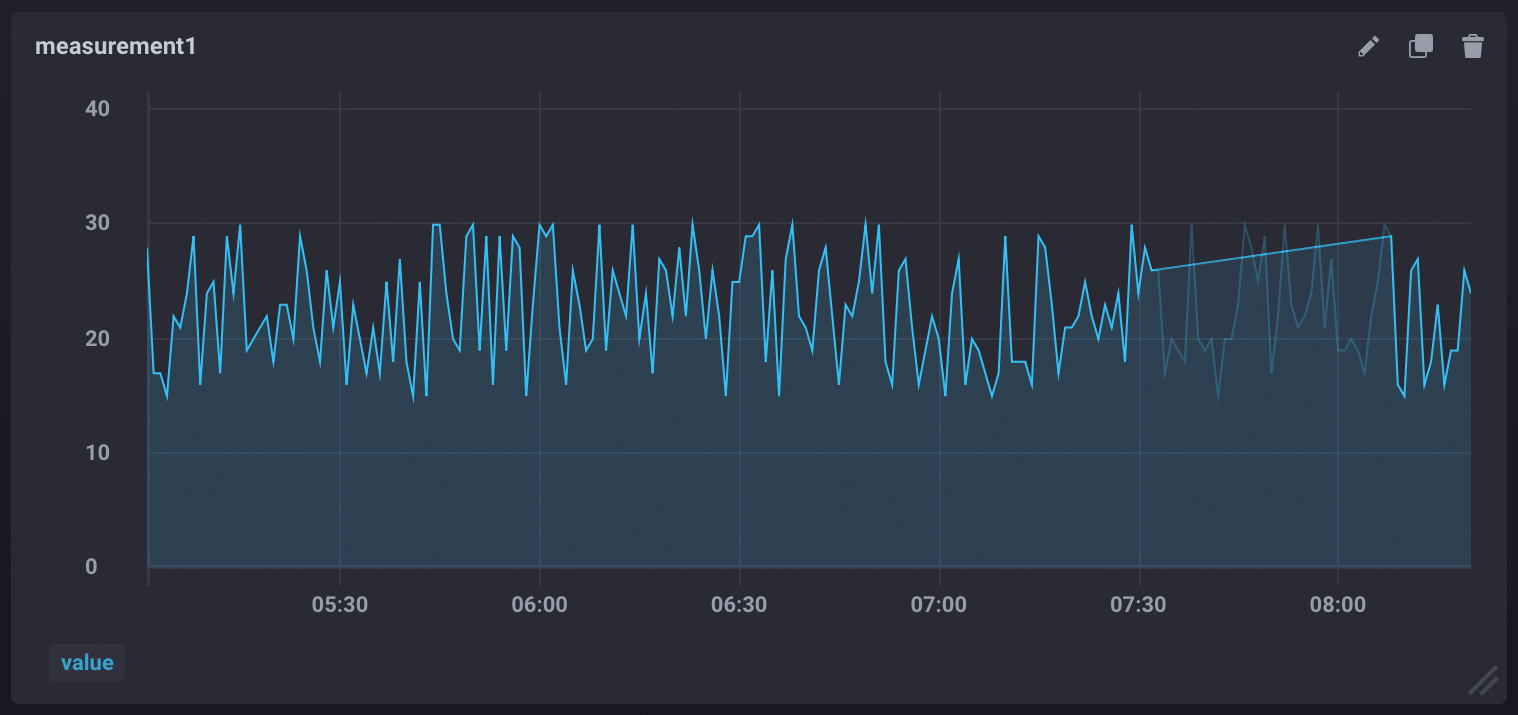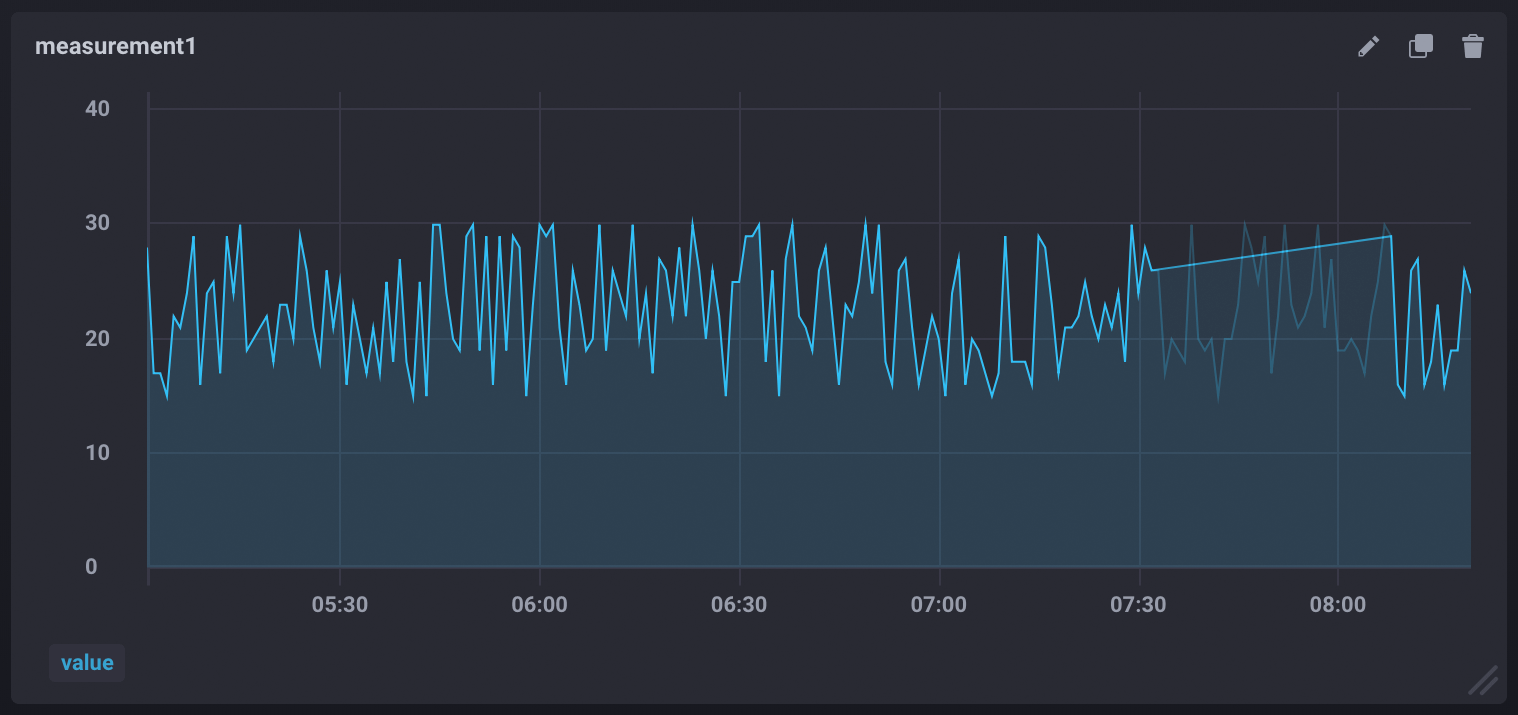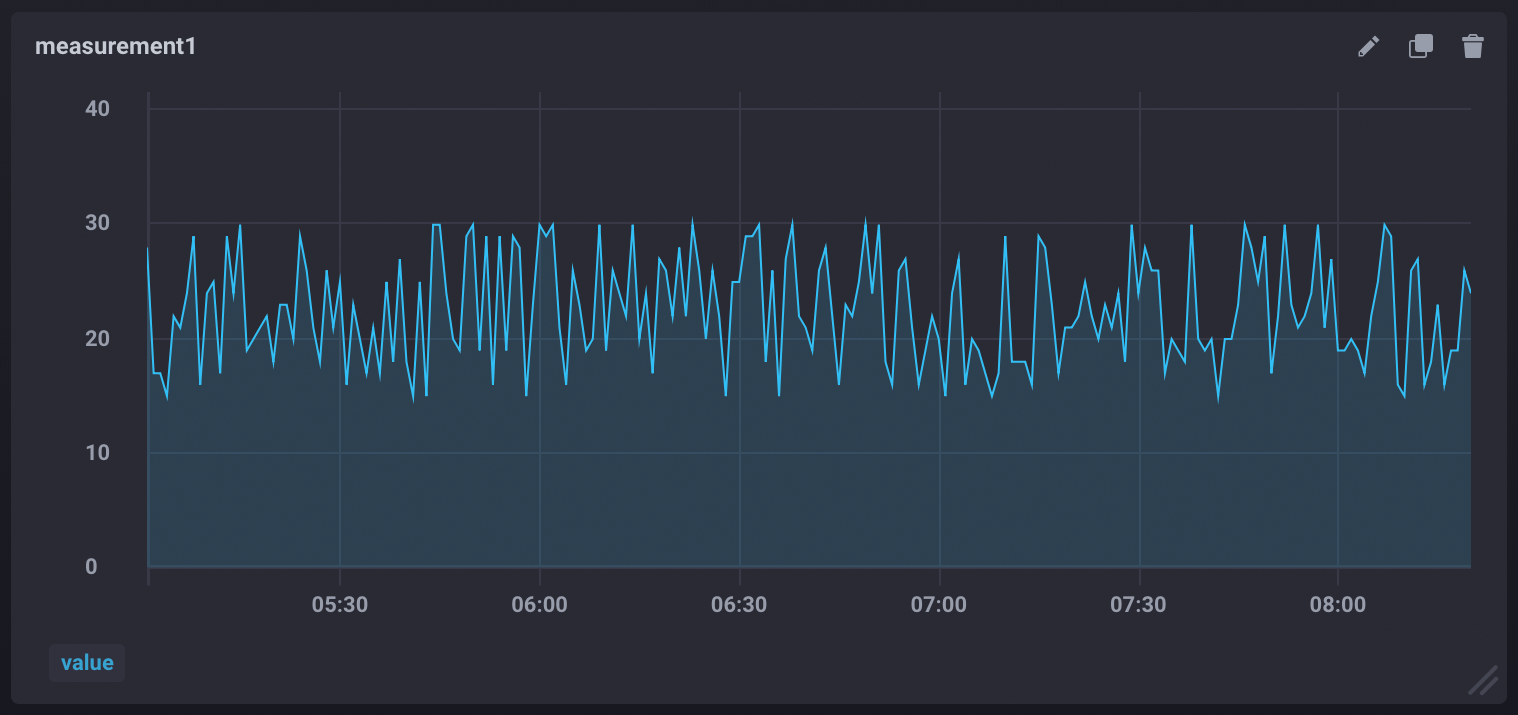
Technical details
Detecting entropy
The Anti-Entropy service runs on each data node and periodically checks its shards’ statuses relative to the next data node in the ownership list. The service creates a “digest” or summary of data in the shards on the node.
For example, assume there are two data nodes in your cluster: node1 and node2.
Both node1 and node2 own shard1 so shard1 is replicated across each.
When a status check runs, node1 will ask node2 when shard1 was last modified.
If the reported modification time differs from the previous check, then
node1 asks node2 for a new digest of shard1, checks for differences (performs a “diff”) between the shard1 digest for node2 and the local shard1 digest.
If a difference exists, shard1 is flagged as having entropy.
Repairing entropy
If during a status check a node determines the next node is completely missing a shard,
it immediately adds the missing shard to the repair queue.
A background routine monitors the queue and begins the repair process as new shards are added to it.
Repair requests are pulled from the queue by the background process and repaired using a copy shard operation.
Currently, shards that are present on both nodes but contain different data are not automatically queued for repair. A user must make the request via
influxd-ctl entropy repair <shard ID>. For more information, see Detecting and repairing entropy below.
Using node1 and node2 from the earlier example, node1 asks node2 for a digest of shard1.
node1 diffs its own local shard1 digest and node2’s shard1 digest,
then creates a new digest containing only the differences (the diff digest).
The diff digest is used to create a patch containing only the data node2 is missing.
node1 sends the patch to node2 and instructs it to apply it.
Once node2 finishes applying the patch, it queues a repair for shard1 locally.
The “node-to-node” shard repair continues until it runs on every data node that owns the shard in need of repair.
Repair order
Repairs between shard owners happen in a deterministic order. This doesn’t mean repairs always start on node 1 and then follow a specific node order. Repairs are viewed at the shard level. Each shard has a list of owners and the repairs for a particular shard will happen in a deterministic order among its owners.
When the Anti-Entropy service on any data node receives a repair request for a shard, it determines which owner node is the first in the deterministic order and forwards the request to that node. The request is now queued on the first owner.
The first owner’s repair processor pulls it from the queue, detects the differences between the local copy of the shard with the copy of the same shard on the next owner in the deterministic order, then generates a patch from that difference. The first owner then makes an RPC call to the next owner instructing it to apply the patch to its copy of the shard.
Once the next owner has successfully applied the patch, it adds that shard to the Anti-Entropy repair queue. A list of “visited” nodes follows the repair through the list of owners. Each owner will check the list to detect when the repair has cycled through all owners, at which point the repair is finished.
Hot shards
The Anti-Entropy service does its best to avoid hot shards (shards that are currently receiving writes) because they change quickly. While write replication between shard owner nodes (with a replication factor greater than 1) typically happens in milliseconds, this slight difference is still enough to cause the appearance of entropy where there is none.
Because the Anti-Entropy service repairs only cold shards, unexpected effects can occur. Consider the following scenario:
- A shard goes cold.
- Anti-Entropy detects entropy.
- Entropy is reported by the Anti-Entropy
/statusAPI or with theinfluxd-ctl entropy showcommand. - Shard takes a write, gets compacted, or something else causes it to go hot. These actions are out of Anti-Entropy’s control.
- A repair is requested, but is ignored because the shard is now hot.
In this example, you would have to periodically request a repair of the shard until it either shows as being in the queue, being repaired, or no longer in the list of shards with entropy.
Configuration
The configuration settings for the Anti-Entropy service are described in Anti-Entropy settings section of the data node configuration.
To enable the Anti-Entropy service, change the default value of the [anti-entropy].enabled = false setting to true in the influxdb.conf file of each of your data nodes.
Command line tools for managing entropy
Note: The Anti-Entropy service is disabled by default and must be enabled before using these commands.
The influxd-ctl entropy command enables you to manage entropy among shards in a cluster.
It includes the following subcommands:
show
Lists shards that are in an inconsistent state and in need of repair as well as shards currently in the repair queue.
influxd-ctl entropy showrepair
Queues a shard for repair.
It requires a Shard ID which is provided in the show output.
influxd-ctl entropy repair <shardID>Repairing entropy in a shard is an asynchronous operation. This command will return quickly as it only adds a shard to the repair queue. Queuing shards for repair is idempotent. There is no harm in making multiple requests to repair the same shard even if it is already queued, currently being repaired, or not in need of repair.
kill-repair
Removes a shard from the repair queue.
It requires a Shard ID which is provided in the show output.
influxd-ctl entropy kill-repair <shardID>This only applies to shards in the repair queue. It does not cancel repairs on nodes that are in the process of being repaired. Once a repair has started, requests to cancel it are ignored.
Stopping an entropy repair for a missing shard operation is not currently supported. It may be possible to stop repairs for missing shards with the
influxd-ctl kill-copy-shardcommand.
InfluxDB Anti-Entropy API
The Anti-Entropy service uses an API for managing and monitoring entropy. Details on the available API endpoints can be found in The InfluxDB Anti-Entropy API.
Use cases
Common use cases for the Anti-Entropy service include detecting and repairing entropy, replacing unresponsive data nodes, replacing data nodes for upgrades and maintenance, and eliminating entropy in active shards.
Detecting and repairing entropy
Periodically, you may want to see if shards in your cluster have entropy or are
inconsistent with other shards in the shard group.
Use the influxd-ctl entropy show command to list all shards with detected entropy:
influxd-ctl entropy show
Entropy
==========
ID Database Retention Policy Start End Expires Status
21179 statsdb 1hour 2017-10-09 00:00:00 +0000 UTC 2017-10-16 00:00:00 +0000 UTC 2018-10-22 00:00:00 +0000 UTC diff
25165 statsdb 1hour 2017-11-20 00:00:00 +0000 UTC 2017-11-27 00:00:00 +0000 UTC 2018-12-03 00:00:00 +0000 UTC diffThen use the influxd-ctl entropy repair command to add the shards with entropy
to the repair queue:
influxd-ctl entropy repair 21179
Repair Shard 21179 queued
influxd-ctl entropy repair 25165
Repair Shard 25165 queuedCheck on the status of the repair queue with the influxd-ctl entropy show command:
influxd-ctl entropy show
Entropy
==========
ID Database Retention Policy Start End Expires Status
21179 statsdb 1hour 2017-10-09 00:00:00 +0000 UTC 2017-10-16 00:00:00 +0000 UTC 2018-10-22 00:00:00 +0000 UTC diff
25165 statsdb 1hour 2017-11-20 00:00:00 +0000 UTC 2017-11-27 00:00:00 +0000 UTC 2018-12-03 00:00:00 +0000 UTC diff
Queued Shards: [21179 25165]Replacing an unresponsive data node
If a data node suddenly disappears due to a catastrophic hardware failure or for any other reason, as soon as a new data node is online, the Anti-Entropy service will copy the correct shards to the new replacement node. The time it takes for the copying to complete is determined by the number of shards to be copied and how much data is stored in each.
View the Replacing Data Nodes documentation for instructions on replacing data nodes in your InfluxDB Enterprise cluster.
Replacing a machine that is running a data node
Perhaps you are replacing a machine that is being decommissioned, upgrading hardware, or something else entirely. The Anti-Entropy service will automatically copy shards to the new machines.
Once you have successfully run the influxd-ctl update-data command, you are free
to shut down the retired node without causing any interruption to the cluster.
The Anti-Entropy process will continue copying the appropriate shards from the
remaining replicas in the cluster.
Fixing entropy in active shards
In rare cases, the currently active shard, or the shard to which new data is
currently being written, may find itself with inconsistent data.
Because the anti-entropy process can’t write to hot shards, you must stop writes to the new
shard using the influxd-ctl truncate-shards command,
then add the inconsistent shard to the entropy repair queue:
# Truncate hot shards
influxd-ctl truncate-shards
# Show shards with entropy
influxd-ctl entropy show
Entropy
==========
ID Database Retention Policy Start End Expires Status
21179 statsdb 1hour 2018-06-06 12:00:00 +0000 UTC 2018-06-06 23:44:12 +0000 UTC 2018-12-06 00:00:00 +0000 UTC diff
# Add the inconsistent shard to the repair queue
influxd-ctl entropy repair 21179Troubleshooting
Queued repairs are not being processed
The primary reason a repair in the repair queue isn’t being processed is because it went “hot” after the repair was queued. The Anti-Entropy service only repairs cold shards or shards that are not currently being written to. If the shard is hot, the Anti-Entropy service will wait until it goes cold again before performing the repair.
If the shard is “old” and writes to it are part of a backfill process, you simply
have to wait until the backfill process is finished. If the shard is the active
shard, run truncate-shards to stop writes to active shards. This process is
outlined above.
Anti-Entropy log messages
Below are common messages output by Anti-Entropy along with what they mean.
Checking status
Indicates that the Anti-Entropy process has begun the status check process.
Skipped shards
Indicates that the Anti-Entropy process has skipped a status check on shards because they are currently hot.
Was this page helpful?
Thank you for your feedback!
Support and feedback
Thank you for being part of our community! We welcome and encourage your feedback and bug reports for InfluxDB Enterprise v1 and this documentation. To find support, use the following resources:
Customers with an annual or support contract can contact InfluxData Support.